Attention Agencies and SEO teams: No Coding Required. Works with any CMS. Make thousands to millions of code and content changes in minutes. Manage all your SEO from one dashboard. Install, automate, and scale with AI.
Create site-wide optimization rules and deploy code changes down to individual pages with one button click. Bypass CMS and technical limitations and deploy code and content changes instantly, anywhere on any page. Edit and optimize text, content and code right on the page in your browser and deploy the updates instantly. Do SEO faster, cheaper, and better than ever before.
1
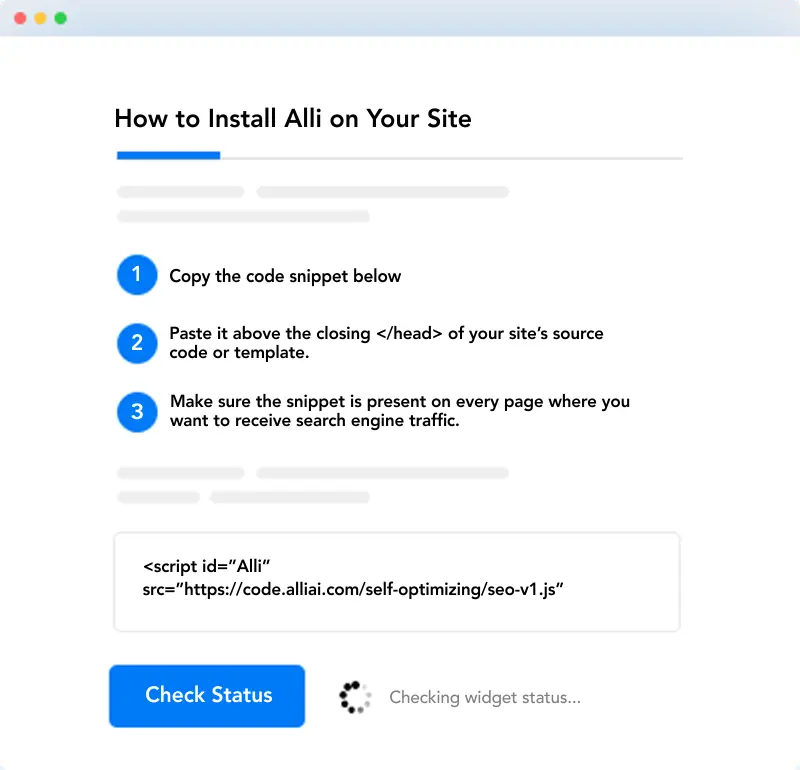
Installation
Add Alli’s Code Snippet to your Site
Install our encrypted code snippet on any website in minutes. Works with all major CMS's and website frameworks.
2
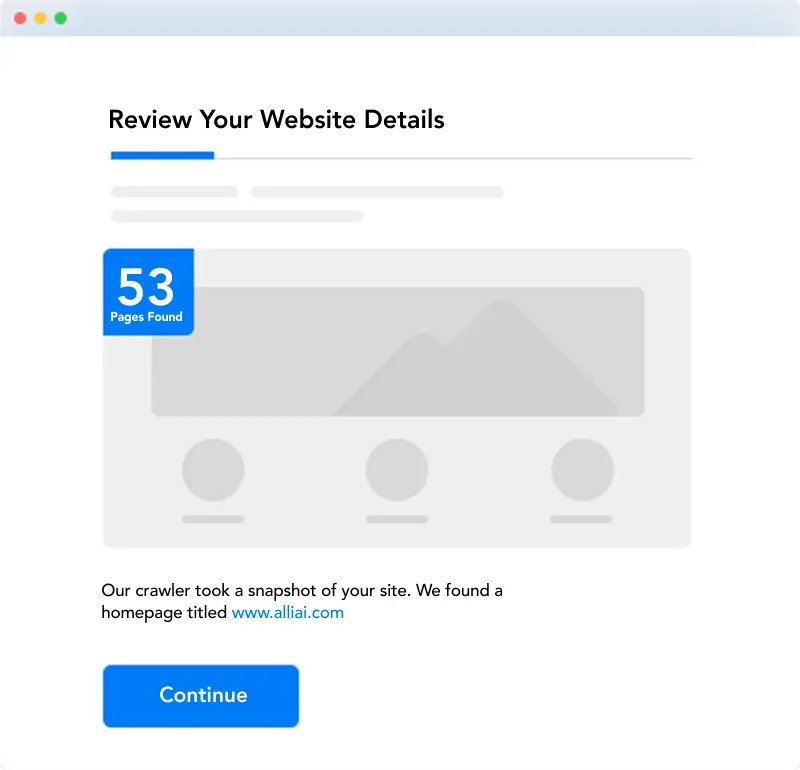
Review
Review Alli's SEO Code & Content Recommendations
You can edit, change, approve or un-approve any automated Recommendation at any time right from the dashboard, and changes will go live immediately.
3
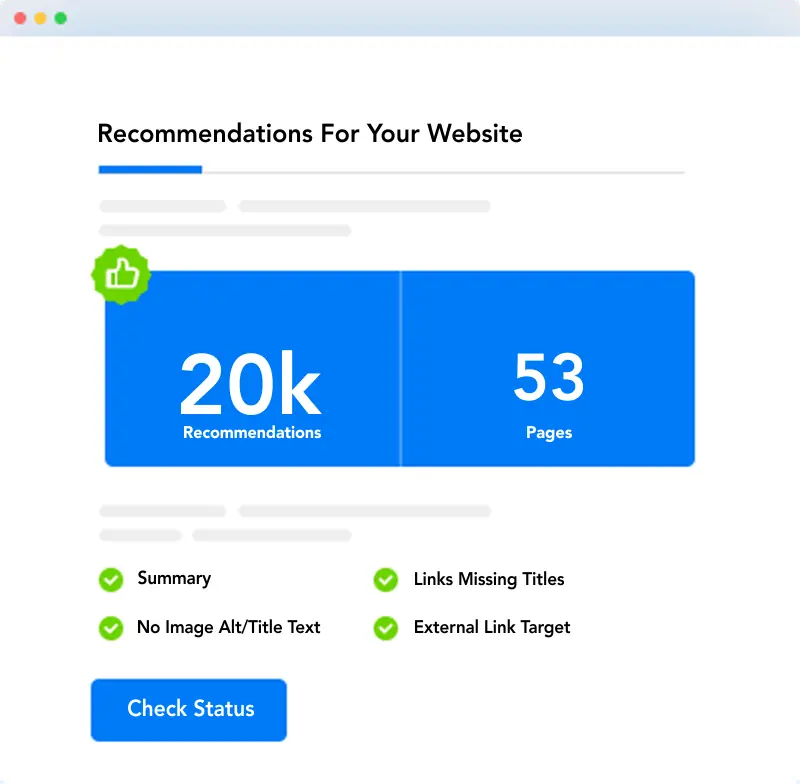
Approve
Approve the Changes, and They'll Be Live in Minutes.
Point, click, deploy. You can deploy hundreds of thousands up to tens of millions of OnPage code optimizations right from the Alli AI dashboard.
Used by More Than 10K Companies
Real-Time, Instant SEO Cloud Deployment
With tens or even hundreds of thousands of pages to optimize across dozens of sites, you don’t have three months to wait for the SEO audit and then another three months for the pull request to go live. Use Alli AI to deploy and test SEO changes instantly. As Ryan Buckley, author of the Parallel Entrepreneur and CEO of Mighty Signals says, “The best time to start SEO is yesterday. The second best time is today.”
It Can Work With Any CMS
From WordPress to Shopify, PrestaShop and back again. As long as you can install our code snippet, Alli can optimize your site.
No Developer, No Tickets
No more waiting weeks for the next release or begging developers to make SEO changes. Take control of any SEO campaign in minutes.
15 Minutes Installation
Follow the step-by-step onboarding wizard and have your website live and configured in the time it takes to brew a pot of coffee.
Customize Automations
Need to change an optimization? Alli lets you turn on, off, edit and customize your changes for every page.
1-10,000,000+ Instant Code Changes
All websites are different, but you can optimize them all with Alli. Depending on your site, you can make anywhere from a thousand to one million optimizations instantly.
Real-Time Verification “highlight” Tool
Monitor your changes anytime with the Highlight tool. See exactly which changes have been made on every page of your site.
It Changes With Your Site
Site redesign? New content? No problem. Alli scans your site regularly to check for changes and update your automations.
Self-Adjust To The Algorithms
The algorithm is always changing, and so is Alli. Alli's automations change as SEO best practices evolve.
One-Click Optimization Approval
No deployments, no SSH, no FTP, no copying and pasting from here to there. Make any and all changes to your site with a mouse click from the Alli dashboard.
Don't just take our word for it,
Our Partners Know the Best.
I manage all my clients with Alli AI.
I manage all my clients with Alli AI.
"I manage all my clients with Alli AI. There's simply no faster way to optimize a website. We've gone from taking months to get tasks done manually to seeing the changes live instantly. Alli AI automates thousands of hours of manual work in minutes, and you can do it all from one dashboard without having to learn and train staff for different CMS for every client."
Lauren Mabra
laurenlabeled.com
Your own in-house SEO director!
“I love SEO, but it takes time. Your software is like having an SEO director in-house!”
Vincent Lambert
Tactick Media
17,000,000 code fixes done instantly!
“We were looking for an affordable way to SEO our site fast. We found Alli and within minutes made 17 million code changes. I’m a full supporter!”
Peter A.
TrivoShop
Dramatically improved organic traffic!
“It’s called Alli AI, and by using it I have dramatically improved the organic traffic to my sites.”
Ryan Buckley
MightySignal
Alli AI has improved our organic traffic by 300%
“Now getting better with AI implementations , about 2 years with this service , can’t say enough about the service and support 👌”
Ramon Diaz
PTI Office Furniture
Great solution to automate SEO for your website
“It was cheaper and provided realtime SEO Changes for over 20,000 recommendations. It would take months to make these changes manually.”
IT Director
Coreslab International
Game changer for SEO!
“Before I would spend all my time reading blogs and watching YouTube vids. I was never sure where to start. Alli gives you an action plan to follow.”
Maarten Schot
YourProfessionals
Jumped to the number three spot!
“Alli AI is great! I had a client at the bottom of page one for a long time…Within seven days he jumped to the number three spot!”
Bill Mabra
BuyPlaya.com
We have been climbing in the rankings
“They deliver a winning service and I highly recommend you give Alli AI a try.”
Luke Anderson
Social Security Branch
Alli AI is a great SEO coach!
“I landed a customer last week. He followed one of the backlinks that Alli told me to create right back to my website!”
Todd
Anonymous
Now ranking 1st for our most important keywords!
“Alli has taken all the confusion out of SEO. It made it very simple to know exactly what to execute.”
Arie Lindenburg
SurveySwap
Fun platform to explore
“It’s fun platform to explore, with a compelling design. Good SEO takes a tremendous amount of work, but this platform somehow “gamifies” it and makes it far less daunting.”
Eric G
Facebook
Alli AI makes SEO friendly and enjoyable
“My favourite part was step-by-step instructions on getting backlinks! I definitely recommend Alli. :)”
Marie Campbell Beausoleil
JustPlainMarie
Game changer for SEO consultants and agencies
“My favorite thing is how enjoyable it is to go through the suggested tasks, and how they prioritize their tasks to have the biggest impact on your SEO.”
Benjamin A.
G2
Use an algorithm to match an algorithm.
“Some of our keywords have moved 60 places, all generic. We have page one rankings. Compared to our previous SEO spend, this is fantastic value for the money.”